Navigating the sprawling landscape of cloud computing means more than just picking a provider; it means strategically placing your digital assets. Initial pricing and availability across regions are not just line items on an invoice—they are fundamental pillars of your cloud cost strategy, directly influencing performance, compliance, and ultimately, your bottom line. Ignoring these geographic nuances can lead to ballooning expenses, sluggish applications, and regulatory headaches.
This guide will demystify the complexities of cloud geography, equipping you with the knowledge to make informed decisions that optimize both cost and performance.
At a Glance: Key Takeaways for Cloud Geography
- Cloud service costs can vary by over 30% between different geographical regions due to local economics, infrastructure, taxes, and demand.
- Data transfer costs, especially between regions, are often overlooked and can quickly accumulate.
- Network latency directly impacts application performance and indirectly increases operational costs through inefficiencies.
- Local laws (data residency, protection, taxes) significantly influence where you can deploy and how much it costs, potentially requiring specific regional deployments.
- Cloud Regions provide isolated geographical areas for deploying applications, offering low-latency access, compliance, and isolation from widespread failures.
- Availability Zones (AZs) are physically separate, isolated locations within a single region, providing high availability and disaster recovery through redundancy.
- Investing in resilience via multi-AZ and multi-region deployments can prevent costly downtime, with 98% of organizations estimating over $100,000 in losses for just one hour of outage.
- Workload optimization strategies like auto-scaling, load balancing, and using cost analysis tools are crucial for maximizing resource utilization and minimizing expenses.
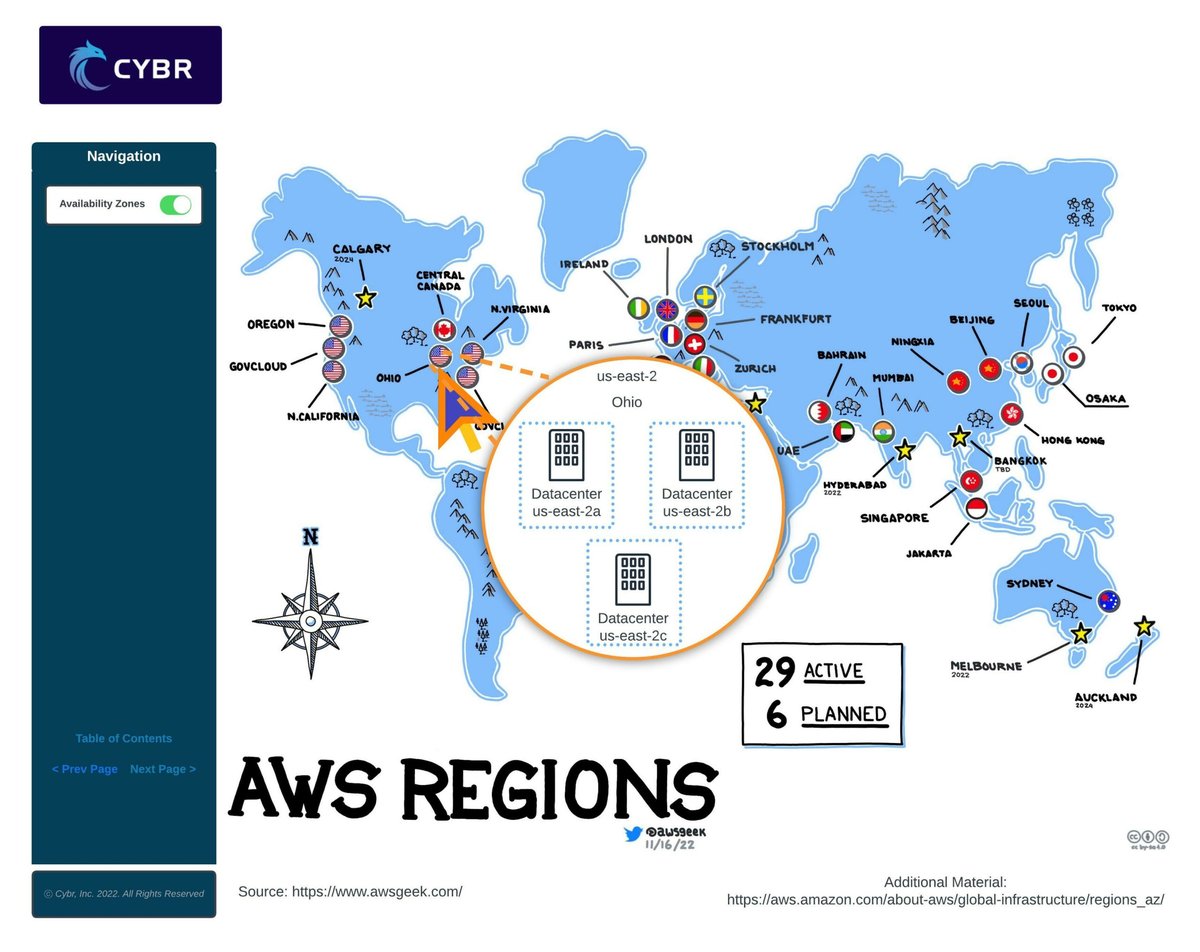
Understanding the Cloud's Global Footprint: Regions & Availability Zones
Before we dive into the financial implications, let's establish a clear understanding of the cloud's physical layout. Cloud providers segment their global infrastructure into distinct geographical areas, each designed with specific purposes in mind.
Cloud Regions: Your Global Hubs
A cloud Region is essentially a large, self-contained geographical area where a cloud provider has established multiple data centers. Think of it as a sovereign territory within the cloud provider’s empire, strategically located to serve specific user bases or regulatory requirements.
Regions are designed with several critical functions in mind:
- Low-Latency Access: By deploying your applications in a region geographically close to your users or employees, you drastically reduce the time it takes for data to travel. For instance, an application hosted in a Western Europe region would offer superior responsiveness for users in London, Berlin, or Paris compared to one hosted across the Atlantic. This direct impact on user experience is often a non-negotiable factor for performance-critical applications.
- Compliance with Local Laws: This is a major driver for regional choice. Many industries and nations have strict data residency or protection regulations. An EU healthcare provider, for example, must deploy Electronic Health Records (EHR) data within an EU region to adhere to GDPR (General Data Protection Regulation) requirements. Regions provide the infrastructure to satisfy these mandates.
- Isolation and Resilience: Regions are built to be isolated from one another. This means that a catastrophic failure or natural disaster in one region (eperhaps a severe typhoon hitting a data center in Japan) does not automatically affect your services deployed in other regions, such as the US or Europe. This inherent isolation ensures a critical layer of service continuity and disaster recovery.
- Flexible Scaling: Within a region, resources are dynamically allocated based on demand and availability. This allows for flexible scaling—you can quickly provision additional compute resources to handle a sudden surge in traffic during a holiday peak usage event, then scale back down when demand subsides, optimizing costs.
Consider an e-commerce platform with a global customer base. They might deploy their primary infrastructure in a US region to serve North American customers, a secondary deployment in an EU region to ensure GDPR compliance and low latency for European users, and a third in a Japan region for their Asian market. This multi-regional strategy ensures optimal performance, regulatory adherence, and resilience worldwide.
Availability Zones: Redundancy Within Regions
While Regions provide broad geographical distribution, Availability Zones (AZs) take resilience a step further. AZs are physically separated, isolated locations within a single cloud region. They are distinct data centers, often several miles apart, each with its own independent power, cooling, and networking. Crucially, they are connected through low-latency, high-throughput networks.
This internal architecture serves two primary purposes:
- Rapid Data Exchange: The close proximity and high-speed connections between AZs enable rapid data synchronization. This is essential for distributed applications that require near real-time data consistency, such as online gaming platform servers or financial trading systems, where even milliseconds can matter.
- High Availability & Disaster Recovery: The core benefit of AZs is enhanced reliability. By replicating your data and deploying application instances across multiple AZs within a region, you ensure quick recovery and minimal data loss in the event of a localized failure. If one AZ experiences an outage (e.g., due to a localized power grid failure), your application can automatically failover to instances running in another AZ within the same region, maintaining service continuity. A healthcare provider, for instance, might deploy their primary EHR system in AZ1, a real-time replica in AZ2, and a tertiary backup in AZ3 for additional redundancy and peace of mind.
This multi-AZ strategy is foundational for building highly available and fault-tolerant applications, protecting against single points of failure within a cloud region.
The Sticker Shock Isn't Always the Full Story: Regional Pricing Dynamics
You might assume that a virtual machine (VM) of a certain specification would cost the same everywhere, but that's far from the truth. The financial aspects of cloud solutions vary significantly by location, and understanding these regional variations is paramount for smart budgeting.
Why Prices Swing: Unpacking the Variables
Cloud service pricing isn't a flat global rate. Price differences between regions can exceed 30%, meaning a service costing $100 in one area could be as low as $70 in another. This substantial divergence is driven by a complex interplay of factors:
- Infrastructure Costs: Building and maintaining data centers in different parts of the world comes with varying costs for land, construction, hardware, and energy.
- Local Economic Conditions: The cost of labor, local taxes, and the overall economic climate in a region directly impact operational expenses for the cloud provider, which are then reflected in service pricing.
- Operational Costs: Electricity, cooling, and physical security all contribute to a provider's operating budget, and these costs differ dramatically across geographies.
- Taxes and Governmental Incentives: Different countries and even specific regions within countries have varying tax structures and may offer incentives to attract data center investment, influencing final pricing.
- Regional Demand and Competition: Supply and demand play a significant role. In regions with high demand and less competition, prices may be higher. Conversely, in highly competitive markets or areas with excess capacity, prices might be driven down.
- Currency Exchange Rates and Inflation: For global providers, fluctuating currency exchange rates can impact pricing in local currencies, as can varying rates of inflation in different economies.
- Geopolitical Stability and Logistics: Operating in politically unstable regions can introduce higher risks and logistical challenges, which can translate into higher operational costs.
- Compliance Hidden Costs: Meeting specific regional regulations can require additional security measures, specialized infrastructure (like local data centers for data residency), more frequent audits, and extensive record-keeping, all of which add to the cost base.
Just as consumer electronics sometimes see staggered releases and varying price points depending on the market—remember the anticipation around an iPad Pro 5th Gen release date and how its pricing might differ by country? Cloud services, too, operate on a complex global economic model, but with far greater implications for your operational budget. Cloud calculators provided by major providers are indispensable tools here, allowing you to estimate expenses across various locations for strategic optimization.
More Than Just Compute: Data Movement and Network Latency
While compute instances often grab the headlines, data transfer costs are a critical, often-overlooked expense that can accumulate rapidly. Moving data between different cloud regions typically incurs significant charges. Frequent transfers across these geographical boundaries can quickly inflate your budget, eroding any savings you might have gained from choosing a cheaper compute region.
Network latency, the delay in data transmission, also significantly impacts performance and costs. For real-time applications (e.g., online gaming, financial trading, video conferencing), even 100 milliseconds of latency can be detrimental, leading to a poor user experience and indirect operational inefficiencies. If your application components are spread across distant regions, the increased latency between them can slow down processes, impacting productivity and potentially requiring more (and thus more expensive) resources to compensate.
To mitigate these costs:
- Centralize Resources: Where possible, consolidate interconnected application components within the same region or even the same Availability Zone to minimize inter-region data transfers.
- Content Delivery Networks (CDNs): For publicly accessible content, CDNs are invaluable. They cache data closer to your users globally, reducing latency and significantly cutting down on data transfer costs by serving content from edge locations rather than your primary data center.
- Dedicated Connections/VPNs: For inter-region communication that must occur, consider dedicated connections or secure VPNs rather than relying solely on the public internet, which can offer more predictable performance and potentially lower costs for high volumes.
Resource Allocation: Supply, Demand, and Local Laws
The pricing of specific cloud resources, such as Virtual Machines (VMs) or specialized services (e.g., managed databases, AI services), also varies by locale. This is due to a confluence of factors:
- Infrastructure Investments: The upfront capital expenditure by the cloud provider in a particular region for specialized hardware or services.
- Operational Costs: The ongoing expense of maintaining those specialized services.
- Market Competition: The presence and pricing strategies of other cloud providers in that region.
- Demand and Availability: High demand for a specific service in a region with limited capacity can drive prices up.
Crucially, local laws and regulations play a profound role, extending far beyond simple data residency: - Data Protection Laws: Regulations like GDPR (EU), CCPA (California), or LGPD (Brazil) dictate how personal data must be handled, stored, and processed. Compliance often necessitates deploying infrastructure in specific regions, which can increase costs due to requirements for enhanced security, specific data encryption, or audit trails.
- Data Residency Requirements: Some industries (e.g., finance, government) or nations mandate that certain data must physically reside within their borders. This forces organizations to deploy in specific regions, regardless of potential cost savings elsewhere.
- Tax Regulations: Local sales taxes, VAT, or other levies apply to cloud services, differing by region and impacting your total expenditure.
- Environmental Regulations: Some regions have stricter environmental standards for data center operations (e.g., energy efficiency, renewable energy usage), which can increase compliance costs.
Non-compliance with these regulations can lead to severe penalties, reputational damage, and costly legal battles. Furthermore, regulations can impact data transfer protocols, potentially increasing latency if data must be routed through specific compliance checkpoints or encrypted with particular standards before crossing borders.
Building for Resilience: High Availability and Disaster Recovery
While cost optimization is key, it should never come at the expense of resilience. Implementing isolated infrastructure segments by distributing services across distinct locations (Regions and Availability Zones) is fundamental for enhancing resilience, operational stability, fault tolerance, and significantly reducing downtime.
Beyond Uptime: The True Cost of Downtime
The financial impact of downtime can be catastrophic. According to industry reports, a staggering 98% of organizations believe that just one hour of downtime can cost them over $100,000. For larger enterprises, this figure can quickly climb into the millions. This doesn't just include lost revenue; it encompasses damaged reputation, lost customer trust, regulatory fines, and recovery costs. The meticulous planning required for cloud resilience stands in stark contrast to simpler product launches. While consumer tech enthusiasts might eagerly await an iPad Pro 5th Gen release date, businesses must meticulously plan infrastructure deployments across regions and AZs to ensure continuous service, where a single hour of downtime can cost upwards of $100,000.
Multi-Layered Protection: Strategies for Continuous Operation
Achieving high availability requires a multi-layered approach that builds resilience into every aspect of your cloud architecture:
- Redundancy: This is the bedrock of high availability. It involves duplicating critical components of your infrastructure (e.g., VMs, databases, network connections) within an AZ, across multiple AZs within a region, and even across multiple regions. If one component fails, redundant components seamlessly take over.
- Automated Failover: Systems must be designed to detect failures instantaneously and automatically reroute traffic and workloads to healthy redundant resources without manual intervention. This ensures rapid recovery and minimizes service disruption.
- Geographic Distribution of Resources: As discussed, leveraging multiple AZs within a region protects against localized outages, while distributing across multiple regions guards against widespread disasters. This prevents single points of failure at any level.
- Regular Backups and Recovery Plans: Consistent, automated backups of data are essential. More importantly, comprehensive disaster recovery plans must be in place, outlining the steps, roles, and responsibilities for restoring services in a crisis.
- Consistent Testing: A disaster recovery plan is only as good as its last test. Regular testing of failover mechanisms and recovery procedures is crucial to identify weaknesses, train teams, and ensure that the plan works when it's truly needed.
This approach not only protects against local incidents but also significantly aids in load balancing, distributing user traffic efficiently across available resources, and can help reduce compliance-related costs by up to 30% by centralizing certain data processing within compliant regions.
The TCO Perspective: Investing in Stability
While the initial investment in robust, multi-AZ, multi-region infrastructure might seem higher, a comprehensive Total Cost of Ownership (TCO) analysis often reveals that the financial benefits of preventing downtime and ensuring continuity far outweigh these outlays. Redundancy minimizes downtime and enhances reliability, optimizing expenses by preventing outages. Monitoring systems and automated failover capabilities reduce the need for costly manual intervention and faster repair times, further optimizing expenses. Proactive investment in resilience is, therefore, not just an IT expenditure but a strategic business decision that protects revenue, reputation, and customer trust.
Strategic Optimization: Smart Workload Placement and Management
Once you understand the geography and pricing dynamics, the next step is to actively optimize your cloud workloads to maximize resource utilization and minimize expenses. This involves strategic planning, continuous monitoring, and agile adjustments to resource allocation.
Right-Sizing Your Cloud: Workload Optimization Strategies
Optimizing workloads is a continuous process that can yield substantial savings. Here are key strategies and their potential benefits:
- Auto-scaling: Dynamically adjusts the number of compute resources (e.g., VMs, containers) based on real-time demand.
- Benefit: Prevents over-provisioning during low demand and ensures sufficient capacity during peak times.
- Potential Savings: 20-30%
- Load Balancing: Evenly distributes incoming network traffic across multiple servers or resources, preventing any single resource from becoming a bottleneck.
- Benefit: Improves application performance, reliability, and allows efficient scaling.
- Potential Savings: 15-25%
- Resource Tagging: Applying metadata (tags) to cloud resources for better categorization, tracking, and management.
- Benefit: Enables granular cost allocation, identifies orphaned or underutilized resources, and improves governance.
- Potential Savings: 10-20%
- Cost Analysis Tools: Utilizing cloud provider tools or third-party solutions to monitor, analyze, and report on cloud spending.
- Benefit: Identifies waste, provides insights into cost drivers, and helps enforce budget limits.
- Potential Savings: 15-35%
Key actions for effective workload optimization include:
- Assess Existing Workloads: Understand the performance characteristics, resource requirements, and traffic patterns of your applications.
- Adopt Multi-Tiered Architectures: Separate application layers (web, application, database) into distinct components that can be scaled independently, often in different resource types or even AZs.
- Implement Auto-scaling: Configure rules for automatically adding or removing resources based on metrics like CPU utilization, memory, or network traffic.
- Leverage Analytics Tools: Use built-in cloud monitoring and cost management tools to gain visibility into resource usage and spending patterns.
- Review Deployment Patterns: Regularly evaluate if your current deployments are still optimal for current demand and evolving requirements.
- Utilize Managed Services: Whenever possible, opt for fully managed services (e.g., managed databases, serverless functions) to offload operational overhead and often achieve better cost-efficiency for specific tasks.
- Leverage Serverless Architectures: For event-driven or intermittent workloads, serverless functions can significantly reduce costs as you only pay for the exact compute time consumed.
Choosing Wisely: Best Practices for Regions and AZs
Making the right choices for your cloud deployments involves strategic thinking about both cost and operational efficiency. Here are some best practices to guide your decisions:
- Deploy Applications Across Multiple Regions for Global Reach: For applications serving a global user base, deploying infrastructure in multiple strategic regions can dramatically reduce latency for users worldwide. This not only improves user experience but also helps comply with local regulations and provides a stronger disaster recovery posture against widespread regional outages.
- Choose Regions Based on a Thorough Cost Optimization and Compliance Assessment: Never default to the nearest region or the cheapest one without a complete analysis. Evaluate the costs of compute, storage, data transfer, and specialized services across various potential regions. Simultaneously, ensure that your chosen regions meet all relevant data residency, privacy, and industry-specific compliance requirements. The ideal region balances cost-effectiveness with regulatory adherence and performance needs.
- Utilize Low-Latency Connections Between AZs and Prefer Dedicated Connections for Inter-Region Communication: Within a region, leverage the high-speed, low-latency network connections between Availability Zones for efficient data exchange within your application architecture. For critical inter-region communication, minimize reliance on the public internet. Instead, prefer dedicated cloud interconnects, direct connections, or secure VPNs. These options offer more predictable performance, enhanced security, and often better cost-efficiency for high-volume transfers compared to public internet egress charges.
- Regularly Monitor Resource Health Across AZs and Regions: Implement robust monitoring and alerting systems to continuously track the health, performance, and utilization of your resources across all deployed AZs and regions. This proactive approach allows you to quickly identify potential failures, performance bottlenecks, or underutilized resources. Prompt detection enables rapid mitigation, preventing minor issues from escalating into significant outages or unnecessary spending.
Navigating the Nuances: Common Questions & Pitfalls
The world of cloud geography and pricing is complex. Here are answers to some common questions and insights into potential pitfalls:
Can I really save 30% by picking a different region?
Yes, absolutely. As the ground truth highlights, service costs can vary by over 30% between different regions. This isn't just theoretical; it's a real-world possibility driven by the varying local economic conditions, infrastructure costs, operational expenses, taxes, and regional demand for cloud resources. While consumer tech announcements, like the excitement surrounding an iPad Pro 5th Gen release date, capture headlines, the real strategic advantage in cloud comes from understanding the granular details of regional pricing and availability. However, these savings must be weighed against latency concerns, data transfer costs (which might negate savings if data moves frequently), and compliance requirements. A cheaper region might not be the best choice if it means non-compliance or a terrible user experience.
What's the biggest hidden cost?
Hands down, data transfer costs, especially for inter-region data movement, are frequently underestimated. While initial compute and storage costs are often budgeted, the ongoing expense of moving data in and out of the cloud, or between distant cloud regions, can quickly accumulate and surprise organizations. Compliance-related costs (e.g., for specific security requirements, audits, or mandated local infrastructure) are another significant hidden expense that can easily be overlooked in initial planning.
How do I balance performance and cost?
This is the perennial challenge in cloud architecture. The key is strategic trade-offs:
- Proximity vs. Price: For user-facing applications, prioritize proximity to users for optimal performance, even if it means slightly higher compute costs.
- CDNs: Use CDNs extensively for static and semi-static content to reduce latency and egress costs.
- Centralization vs. Distribution: Centralize application components that have high interdependencies or require frequent data exchange within a single region/AZ to minimize latency and transfer costs. Only distribute across regions when necessary for global reach, compliance, or disaster recovery.
- Workload Optimization: Employ auto-scaling, right-sizing, and serverless options to pay only for what you use, rather than over-provisioning for peak demand.
Is multi-region always better?
Not necessarily for every workload. While a multi-region strategy offers superior resilience against widespread disasters and better global performance, it also introduces complexity, increases management overhead, and significantly raises costs due to data replication and inter-region data transfer fees. For internal applications with a localized user base, a robust multi-AZ deployment within a single region might provide sufficient high availability at a much lower cost and complexity. The "best" strategy depends entirely on your specific application requirements, RTO/RPO (Recovery Time Objective/Recovery Point Objective) needs, and budget constraints.
Your Action Plan: Architecting for Cost-Efficiency and Resilience
Successfully leveraging the cloud's global infrastructure requires a proactive, informed approach. Unlike eagerly anticipating an iPad Pro 5th Gen release date, your cloud strategy isn't about waiting; it's about proactive design and continuous optimization.
Here's how to move forward:
- Conduct a Comprehensive Regional Cost Analysis: Before deploying, use cloud provider calculators to compare the total estimated costs (compute, storage, network, specialized services) for your specific workload across at least three potential regions. Factor in projected data transfer costs.
- Map Workloads to Compliance Requirements: Clearly identify which data and applications are subject to specific data residency, privacy, or industry-specific regulations. This will dictate your primary region choices for those workloads.
- Design for Multi-AZ Resilience First: For critical applications, always architect for high availability across multiple Availability Zones within your chosen primary region. This is your first line of defense against localized failures.
- Evaluate Multi-Region for Global Reach and Disaster Recovery: Only extend to a multi-region strategy if you have a global user base, stringent disaster recovery requirements against regional outages, or specific compliance needs in different geographies. Understand the added costs and complexity.
- Prioritize Data Transfer Optimization: Implement CDNs for content delivery. Architect applications to minimize inter-region data movement. Consolidate interconnected components to reduce latency and internal transfer costs.
- Implement Continuous Cost Monitoring and Optimization: Cloud costs are dynamic. Use cost management tools, set budgets, and regularly review your spending. Look for opportunities to right-size resources, leverage auto-scaling, and adopt serverless or managed services where appropriate.
- Regularly Test Disaster Recovery Plans: Don't assume your resilience strategy works. Schedule regular, comprehensive testing of your failover and recovery procedures to ensure operational readiness.
By thoughtfully considering initial pricing and availability across regions, and by architecting with resilience and optimization in mind, you can build a cloud strategy that not only performs exceptionally but also delivers predictable, controlled costs, empowering your organization to thrive in the digital age.